macOS 跨进程渲染
去年接到一个研究项目:在 macOS 下实现跨进程渲染。背景现有的单进程应用已经不堪重负,我们希望能把底层 Video/Image 模块单独拆分到一个进程。 这样既能实现最大化利用处理器的性能,也能实现模块之间更好的拆分处理。
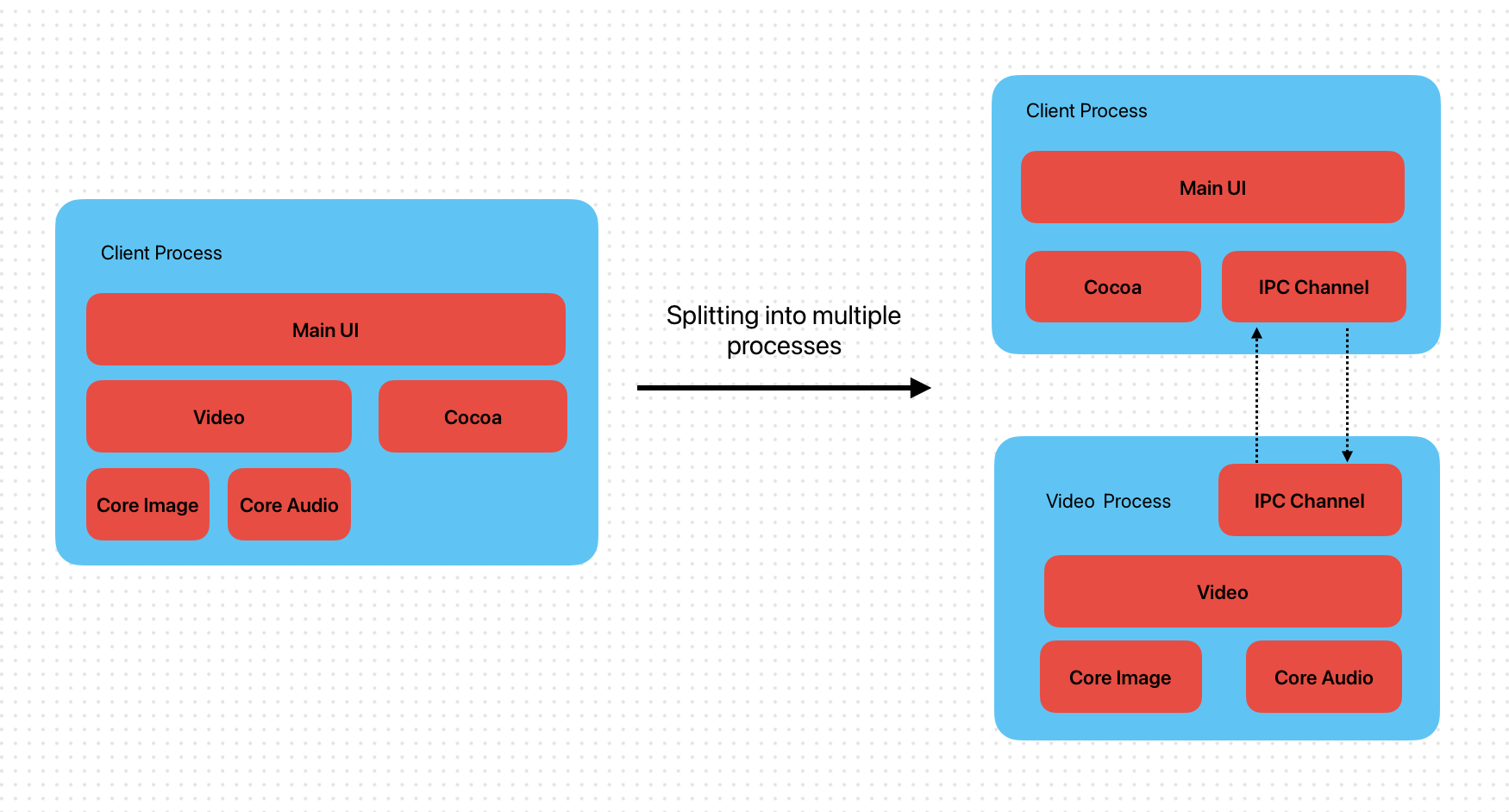
在 Window 平台中我们可以通过在进程间传递 HWND 的句柄实现跨进程渲染,这样就可以将不同进程的 UI 组织在一起,从表象上看起来和单进程几乎没有区别。 遗憾的是 macOS 的 Cocoa 并没有这种高级用法,为了实现跨进程渲染就不得不另寻他法。
常规 IPC 方式
虽然 macOS IPC 不支持传递 View ,但是传递数据肯定是没有任何问题的。因此最开始的想法就是模拟 Win 的操作直接在 IPC 通道里面加一个机制, 专门的来传递 Video 原始数据。然后再在 Client 进程把数据在视图 Render 出来并把视图贴到主视图里面不久可以模拟出 Win 一样的效果了吗?
接下来我就在 Mach Ports、Distributed Notifications、Distributed Objects 这三种消息通道 IPC 里面选择了 DO 来验证,大致流程如下:
- Client 进程创建 C-Server NSConnection 服务
- Client 进程唤起 Video 进程
- Video 进程创建 V-Server NSConnection 服务
- Video 进程连接 C-Server 服务
- Client 进程收到 C-Server 连接请求后连接 V-Server 打通双向通信
- Client 通过 V-Server 订阅 Video 数据流
- Video 进程将数据通过 C-Server 发送到 Client 进程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
// DO NSConnection 通信协议大致如下
@protocol ClientProtocol <NSObject>
@optional
- (void)onServerLaunch:(NSString *)uuid;
- (void)onReceiveBuffer:(NSImage *)bufferImage
userID:(NSString *)userID
height:(NSInteger)height
width:(NSInteger)width;
...
@end
@protocol ServerProtocol <NSObject>
@optional
- (void)onSubscribe:(NSString *)userID;
- (void)onUnsubscribe:(NSString *)userID;
...
@end
但是验证结果非常不理想,首先周消息通道的 IPC 必然涉及到 Memory Copy 。举例来说:1080P、60FPS 质量的视频大概每秒 Copy 量: (1920 * 1080 * 4 * 60) / (1024 * 1024) ≈ 475 MB。哪怕即使是 30FPS 压力也非常的大,CPU 几乎不用处理其他任务。
在发现纯消息通道 IPC 瓶颈后我又更近了一步,如果 Memory Copy 被解决了是不是就可行了呢?所以我在上面的基础上加了共享内存方式来处理这个问题。
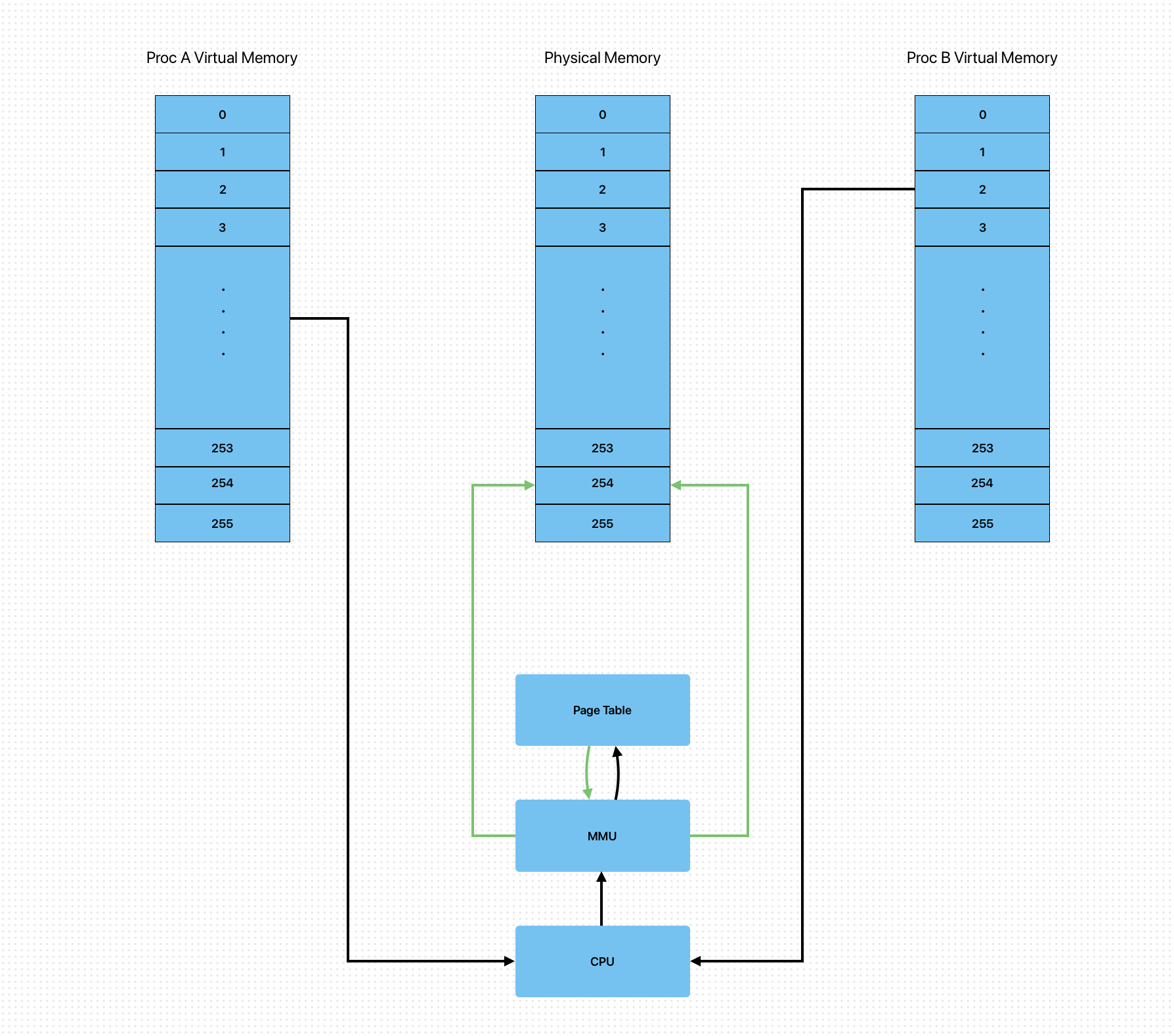
Shared Memory
众所周知每个进程运行时都有自己进程的虚拟内存空间,然后通过 页表 和 MMU 实现虚拟地址和真实物理地址的映射。那么如果我们能够讲同一块物理内存同时映射到两个不同进程的虚拟内存空间中不就可以避免消息通道 IPC 中的多余拷贝了吗?而这个正是 Shared Memory 共享内存 IPC 通信方式原理。
主要代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
@implementation SharedMemoryFileMapping
...
- (BOOL)config:(BOOL)isCreater fileName(NSString *)fileName bufferSize:(NSUInteger)bufferSize {
...
int flag = O_RDWR | O_CREAT;
if !isCreater) {
flag = O_RDONLY;
}
int fd = shm_open(fileName.UTF8String, flag, 0666);
if (fd < 0) {
return NO;
}
if (ftruncate(fd, bufferSize) == -1) {
shm_unlink(fileName.UTF8String);
return NO;
}
_sharedMemId = fd;
...
return YES;
}
- (BOOL)mappingBuffer {
if (_sharedMemId == -1) {
return NO;
}
BOOL ret = YES;
self->currentBuffer = mmap(NULL, _bufferSize, PROT_READ | PROT_WRITE, MAP_SHARED, _sharedMemId, 0);
if (self->currentBuffer == (void *)-1) {
ret = NO;
}
...
return ret;
}
- (void)writeFrameBuffer:(void *)pBuffer size:(NSUInteger)size {
if (self->currentBuffer == NULL || pBuffer == NULL) {
return;
}
const size_t MAX_LIMIT_MEM_SIZE = 100 * 1024 * 1024UL;
const size_t MIN_LIMIT_MEM_SIZE = 1UL;
if (size < MIN_LIMIT_MEM_SIZE || size > MAX_LIMIT_MEM_SIZE || size > _bufferSize || size > kMaxSharedMemorySize) {
return;
}
if (size <= _bufferSize && self->currentBuffer != NULL) {
memcpy(self->currentBuffer, pBuffer, size);
}
}
- (void)readFrameBufffer:(void (^)(void *pBuffer))compeltion {
if (!compeltion) {
return;
}
if (self->currentBuffer == NULL || self->currentBuffer == (void *)-1) {
compeltion(nullptr);
return;
}
compeltion(self->currentBuffer);
}
- (void)cleanUpCurrentBuffer {
if (self->currentBuffer != (void *)-1 && self->currentBuffer != NULL) {
munmap(self->currentBuffer, _bufferSize);
self->currentBuffer = (void *)-1;
_mappingSuccess = NO;
}
}
- (void)unlinkFile {
if (_sharedMemId != -1) {
[self cleanUpCurrentBuffer];
shm_unlink([_fileName UTF8String]);
_sharedMemId = -1;
self.fileName = nil;
}
}
...
@end
这里之所以采用 Memery File + mmap 方式是因为 macOS 默认共享内存大小为 4MB,所以为了更大更大的内存空间只能绕路走一下
1
2
3
4
5
6
7
8
9
➜ ~ sysctl -A | grep shm
kern.sysv.shmmax: 4194304
kern.sysv.shmmin: 1
kern.sysv.shmmni: 32
kern.sysv.shmseg: 8
kern.sysv.shmall: 1024
machdep.pmap.hashmax: 21
security.mac.posixshm_enforce: 1
security.mac.sysvshm_enforce: 1
然后我们再使用信号量或者上面的消息通道作为同步机制,从而避免了 IPC 数据传输过程中的多次拷贝。
不过这个时候另一个问题又暴露出来了:渲染过程依旧会导致 CPU 的高占用,哪怕我们不考虑对数据进行滤镜设置等计算操作。因为在渲染过程中需要将 Buffer 数据对应的 NSImage 对象 Upload 到 GPU 然后一系列处理后又 Download 到 CPU 来 Display。如果期间再添加一下特效等等操作,那么将更加复杂和不可接受。
到了这里感觉只能全程通过 GPU 才能实现理想的跨进程渲染操作了。于是我开始了各种用 Core Image、GPU 这些关键词去网上搜索资料,很快就找到了我想要的突破口。
Taking Advantage of Multiple GPUs WWDC 2010 关于多 GPU 渲染的视频,其中一段关于 IOSurface 的介绍给我打开了新思路。这里我不得不感慨一下 Apple 或者说国外大厂底蕴深厚,十几年前的视频和文档都还能找到,要知道哪个时候我还在上高中,班上只有极少数同学有诺基亚,日常也就是看看 NBA 文字直播,乃不知有 Android,无论 iPhone。
IOSurface
IOSurface 框架提供了一个适合跨进程共享的 framebuffer 对象。它通常被用来允许应用程序将复杂的图像解压缩和绘制逻辑拆分到一个单独的进程中以增强安全性。
上面的描述是 Apple 官方文档对 IOSurface 的总结,从其中我们能看出来 IOSurface 就是为跨进程图像渲染而生。详细点大概就是:IOSurface 是一个由内核管理的纹理内存块,它可以在 GPU 上自动完成显存的分页,并在不同进程之间共享。当跨进程共享时,数据不会被复制。如果我们再配合 Metal 或者 OpenGL 一起使用的话,那么整个渲染过程中数据块都会一直存在于 GPU 中,不存在 CPU 和 GPU 之间的数据 Copy。一句话就是: IOSurface 能够实现跨进程渲染的数据 Zero-Copy,高效到主板冒烟 😂。
IOSurface 创建并绑定到 CVPixelBufferRef:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
CFDictionaryRef empty;
CFMutableDictionaryRef attrs;
empty = CFDictionaryCreate(kCFAllocatorDefault,
NULL,
NULL,
0,
&kCFTypeDictionaryKeyCallBacks,
&kCFTypeDictionaryValueCallBacks); // our empty IOSurface properties dictionary
attrs = CFDictionaryCreateMutable(kCFAllocatorDefault, 1, &kCFTypeDictionaryKeyCallBacks, &kCFTypeDictionaryValueCallBacks);
CFDictionarySetValue(attrs, kCVPixelBufferIOSurfacePropertiesKey, empty);
CVPixelBufferRef pxbuffer = NULL;
CVReturn status = CVPixelBufferCreate(kCFAllocatorDefault, 1280, 720, kCVPixelFormatType_32ARGB, attrs, &pxbuffer);
if (status != kCVReturnSuccess) {
NSLog(@"Operation failed");
CFRelease(empty);
CFRelease(attrs);
return;
}
IOSurfaceRef surfaceRef = CVPixelBufferGetIOSurface(pxbuffer);
CFRelease(empty);
CFRelease(attrs);
完成上诉绑定操作后我们再将像素数据写到 pxbuffer 变量中,然后再通过 IOSurfaceCreateXPCObject 或者 IOSurfaceCreateMachPort 对应的 IPC 方式将 surfaceRef 在不同进程中进行传递。最终的效果如下: